


随着大数据技术的飞速发展,数据实时同步成为企业信息化建设中的关键环节,本文将带你走进Hive实时同步至Kafka的世界,深入了解其原理、优势及实际操作步骤,助你轻松驾驭大数据时代的浪潮。
什么是Hive与Kafka?
Hive
Hive是Hadoop生态系统中的一个数据仓库工具,用于处理和分析大规模数据,它提供了一个SQL查询接口(HiveQL),允许开发者进行数据查询和分析操作,Hive适用于离线数据处理,但在实时数据处理方面存在局限性。
Kafka
Kafka是一个分布式流处理平台,用于构建实时数据流管道和流应用,它允许发布和订阅记录流,支持高并发、高吞吐量的数据传输,Kafka适用于实时数据处理场景,如实时同步、事件驱动等。
为何需要Hive实时同步至Kafka?
随着企业对实时数据的需求日益增长,Hive与Kafka的集成变得越来越重要,Hive实时同步至Kafka可以实现以下目标:
1、弥补Hive在实时数据处理方面的不足。
2、将离线数据与实时数据相结合,提高数据分析的时效性。
3、实现数据的快速流转和共享,支持各种实时业务场景。
Hive实时同步至Kafka的原理与优势
原理:
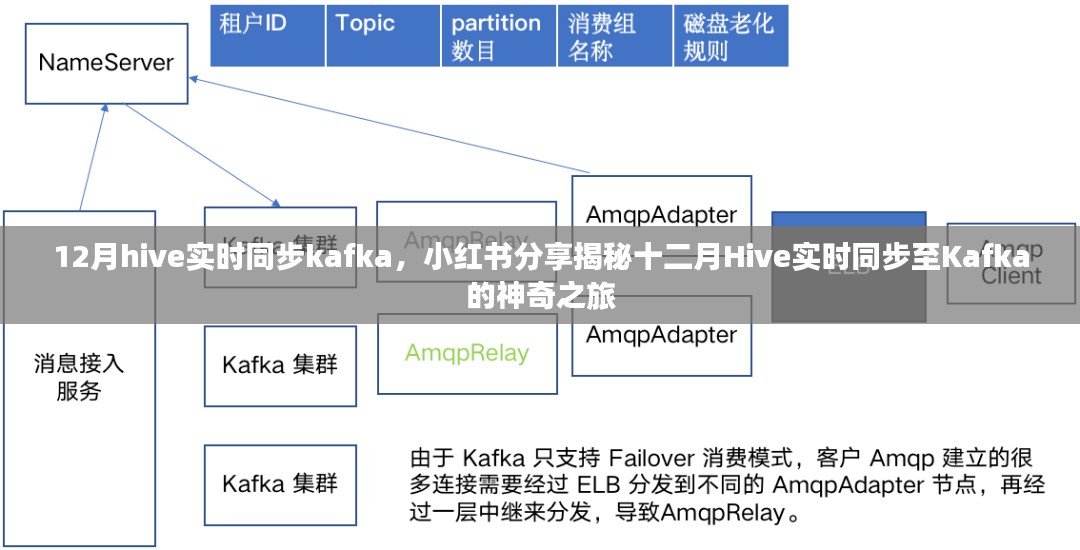
Hive实时同步至Kafka主要依赖于数据流的捕获和传输技术,通过配置Hive将数据变更日志(binlog)捕获并写入Kafka,实现数据的实时同步,这种方式可以实现数据的增量同步,只传输变化的数据,降低网络负载。
优势:
1、时效性高:实现数据的实时同步,满足企业对实时数据的需求。
2、灵活性好:支持多种数据格式和协议,方便与其他系统进行集成。
3、可扩展性强:基于分布式架构,支持大规模数据的处理。
4、可靠性高:采用分布式存储和备份机制,保证数据的安全性和可靠性。
如何实现Hive实时同步至Kafka?
1. 配置Hive捕获数据变更日志(binlog)
需要配置Hive以捕获数据变更日志,这可以通过配置Hive的binlog插件来实现,该插件可以捕获数据的变化并生成binlog文件。
配置Kafka集群并创建Topic
需要配置Kafka集群并创建用于存储Hive数据的Topic,确保Kafka集群能够正常接收和处理数据。
配置数据同步任务并启动服务
配置数据同步任务,将Hive的binlog文件实时同步至Kafka集群,启动服务后,数据将自动进行实时同步,具体配置过程可以参考相关文档或教程进行,这里不再赘述,需要注意的是,在实际操作过程中可能会遇到一些问题,如网络延迟、数据传输错误等,需要根据具体情况进行调试和优化,同时还需要关注数据安全性和可靠性问题确保数据的完整性和准确性,此外还需要对系统进行监控和性能优化以满足业务需求,通过合理配置和优化可以实现高效的Hive实时同步至Kafka提高数据处理和分析的效率为企业带来更大的价值,总之Hive实时同步至Kafka是大数据领域的一个重要应用场景通过掌握相关技术和方法可以更好地应对企业面临的实时数据处理需求实现更加精准和高效的数据分析和管理,让我们一起探索这个神奇的数据世界迎接更多的挑战和机遇!以上就是我们今天的分享希望对大家有所帮助!如果有任何问题或建议请随时与我们联系我们会尽快回复并共同进步!让我们一起驾驭大数据时代的浪潮!
转载请注明来自苏州格致磁业有限公司,本文标题:《揭秘十二月Hive实时同步至Kafka的神奇之旅,小红书分享实战经验分享》










 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...